Hierarchical
Content-based Database of Surveillance Video Data
Aim
Multi camera surveillance systems can accumulate vast quantities of
data over a short period of time when running continuously. In our
research we address the problem of how this data can be efficiently
stored and annotated using a hierarchy of data abstraction layers to
support online queries and event recall.
Background
Surveillance systems are required to record video data continuously, so
in case of an inquiry, personnel can access the video and search for
particular events. Analogue surveillance systems use tapes to store the
video streams. Reviewing the video can be time-consuming, as personnel
has to linearly access the video tapes search for video events.
Automated surveillance systems can store video data in digital
form. However, the amount of uncompressed video data generated by
a single CCTV camera in a day is vast, up to 4 Terabytes. Therefore,
storing and accessing of the data is quite problematic, especially if
storing is required for longer periods or if the system consists of
multiple cameras.
Database Overview
The surveillance database comprises four layers of abstraction:
- Image framelet layer
- Object motion layer
- Semantic description layer
- Meta-data layer
This four-layer hierarchy supports the requirements for real-time
capture and storage of detected moving objects at the lowest level, and
the online query of activity analysis at the highest level. Computer
vision algorithms are employed to automatically acquire the information
at each level of abstraction.
Database Overview:
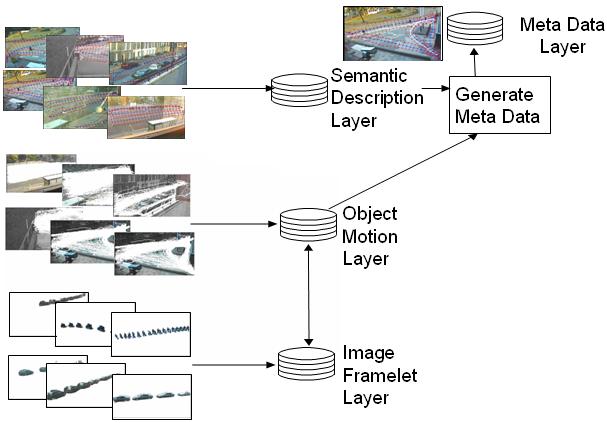
Image Framelet Layer
The image framelet layer is the lowest layer of the database and
aims to represent the raw video, captured by each fixes camera of the
surveillance system.In order to achieve efficient compression of the
video data, an MPEG4-like compression method, based on
background/foreground separation (motion detection), is used. More
specifically, at each frame the system stores image framelets that
correspond to foreground detected objects. Video data can be reviewed
by repositioning the image framelets on a maintained background image.
This approach provides a very efficient compression rate of 1000:1,
much higher than traditional compression techniques such as MJPEG and
MPEG.
Examples of Image Framelets






Object Motion Layer
The object motion layer relates the framelets of the same object in
different frames. The correspondence between framelets is based on the
motion tracking process of the surveillance system, therefore it
can visualised by a trajectory for each tracked object. Object motion
layers are established for each single camera view, based on single
camera motion tracking. A universal object motion layer is also
established for the system virtual field of view, based on multiple
camera motion tracking.
Sets of trajectories (one trajectory
per
object) for different camera views of the system






Semantic Description Layer
The semantic description layer represents static features of the scene,
such as entry/exit zones, paths, junctions, etc. These features are
automatically obtained by unsupervised machine learning
algorithms that are applied on large sets of motion observations.
Because the structure of the scene is closely related to the observed
motion, it can be argued that the semantic description layer summarises
the motion activity of all the observed objects.
Entry/exit zones and paths for
different views of the system






Meta-Data Layer
The meta-data layer links the information of the the lower layers
(image framelet, object motion) to the semantic description layer. It
summarises the information of an object with very few parameters, such
as entry point, exit
point, time of activity, appearance features, and the route taken
through the
FOV.

Applications
- The image framelet layer allows a very efficient compression of
surveillance video. The video can be replayed using a special-purpose
video viewer software.
- The object motion layer provides a mechanism to isolate selected
objects and replay their observed activity. Because the activity of
each foreground object is separated from the the other objects and from
the background, synthetic videos are easily created.
- The existence of the semantic description layer allows the
summarisation of the object motion history with very few parameters.
Because humans interprete object motion in relation to other objects of
the scene, the semantic description layer provides the basis for such
content-based description of motion. The advantage of this approach is
that allows human operators to use context-based queries and the
response to these queries is much faster.
- Finally, the meta-data layer allows the extraction of the motion
descriptors to XML files that then can be used by external applications.
This diagram illustrates how video is
replayed by projecting imageframelets on the background, using the
object motion layer positions

This diagram shows the results of two
queries that ask for objects moving
between specific entry/exit zones

Publications
J. Black, D. Makris, T.J. Ellis, "Hierarchical
Database for a Multi-Camera Surveillance System" in 'Pattern
Analysis and Applications', 7(4) Springer, December, pp. 430-446.
ISBN/ISSN 1433-7541 (2004) abstract
J. Black, T.J. Ellis, D. Makris, "A
Hierarchical Database for Visual Surveillance Applications",
IEEE International Conference on Multimedia and Expo (ICME2004), June,
Taipei, Taiwan, pp. 1571 - 1574. (2004) abstract
download
J. Black, T.J. Ellis, D. Makris, Chapter "A Distributed Database for Effective
Management and Evaluation of CCTV Systems"
in 'Intelligent Distributed Video Surveillance Systems', Edited by S.A
Velastin & P Remagnino, Institution of Electrical Engineers, pp.
55-89. ISBN/ISSN 978-086341-504-3 (2006) abstract
About this work
This work of James
Black, Tim
Ellis and Dimitrios
Makris is part of the IMCASM project funded by EPSRC.