|
|
|
|
Jean-Christophe Nebel
|
|
 |
MEDUSA
|
| General aim |
The identification of situations associated with gun related threats based on behavioural interpretation of CCTV data combining psychological and image processing approaches.
| Project summary |
A key factor in reducing potential gun crime is to detect someone carrying a gun before they can commit a criminal act. This detection can be achieved by the existing, and widespread, CCTV camera network in the UK. However, the performance of operators in interpreting CCTV imagery is variable as they are trying to detect essentially a very rare threat event. We propose the development of a new machine learning system for the detection of individuals carrying guns which will combine both human and machine-based factors. Using selected CCTV footage which depicts people carrying concealed guns, and other control individuals, the proposal will establish what overt and covert cues experienced CCTV operators actually attend to when identifying potential gun-carrying individuals. In parallel, a machine learning approach will establish the machine recognised cues for such individuals. The separate human and machine cues will then be combined to form a new machine learning approach. The system will be capable of learning and reacting to local gun crime factors which will aid its usefulness and deployment capability.
| Research |
|
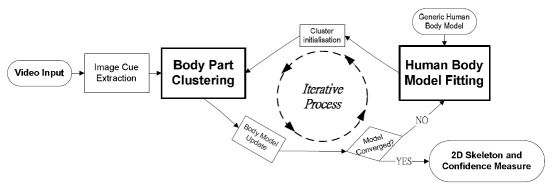
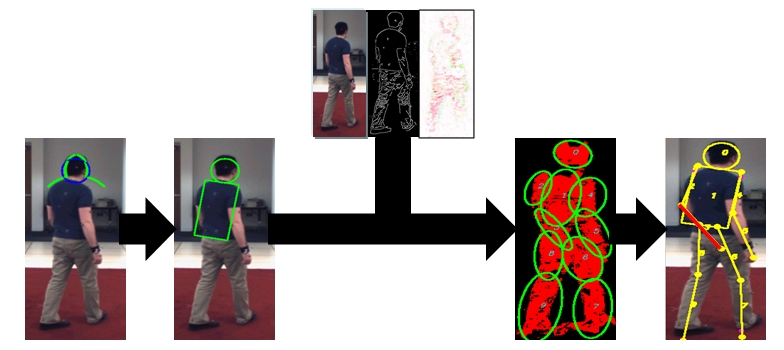
We proposed a novel bottom-up/top-down approach for 2-D human pose recovery from monocular images. The bottom-up module segments body parts based on GMM clustering according to a set of image cues where characteristics of body parts are embedded. The top-down module applies a generic body model to fit on segmented body parts and the body model is resized appropriately based on the clustering results. The bottom-up/top-down modules are integrated in an iterative loop so the output of one module is used as the input of the other module to optimise the final estimate of the pose. The framework neither requires a training stage, nor any prior knowledge of poses and appearance. Once the optimal pose has been found, a probabilistic confidence is generated to evaluate the expected accuracy of the recovered pose.
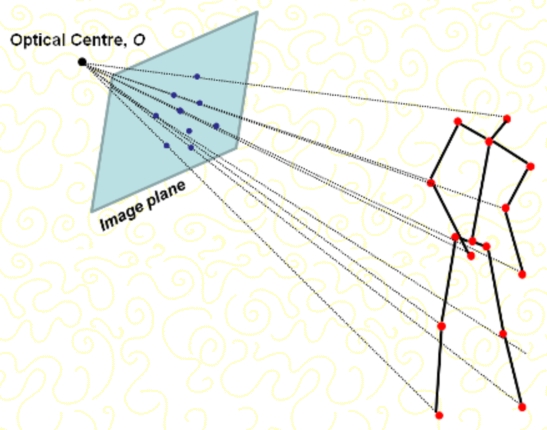
Geometric camera calibration reveals the relationship between the 3D space that is viewed by the camera and its projection on the image plane. Usually, calibration requires the preesence of a known reference object, which makes the process unpracticle in many real scenarios. To lift this strong constraint, that has to be removed for processing real and uncontrolled video sequences. To this end, this work we developed a new calibration framework that is able to calibrate automatically a camera using observed human articulated motions. By analysing positions of key points during a sequence, our technique is able to detect frames where the human body adopts a particular posture, i.e. mid-stance position, which ensures the coplanarity of those key points and therefore allows a successful camera calibration using Tsai's coplanar calibration framework.
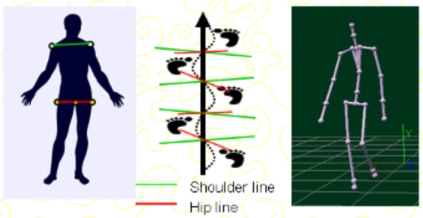
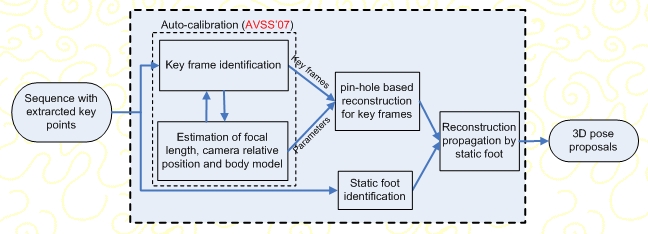
3D pose reconstruction is achieved by exploiting two important constraints observed from human bipedal motion: coplanarity of body key points at the mid-stance position and the presence of a foot on the ground - i.e. static foot - during most bipedal activities. Assuming 2D joint locations have been extracted from a video sequence, the algorithm is able to perform camera auto-calibration on specific frames when the human body adopts particular postures. Then, a simplified pin-hole camera model is used to perform 3D pose reconstruction on the calibrated frames. Finally, the static foot constraint is applied to infer body postures for non-calibrated frames.
| Keywords |
Gun crime, visual surveillance, abnormal behaviour, human cues, machine learning
| Media |
|
||
|
||
|
||
|
||
|
| Publications |